Edge Computing in Autonomous Vehicles A Founder's Guide

When we talk about edge computing in autonomous vehicles, we're really talking about processing critical data right there inside the car, instead of shipping it off to some far-away cloud server. This is what enables instant, real-time decisions—like slamming on the brakes for a pedestrian—which is an absolute must-have for safe self-driving technology.
Why Milliseconds Matter in Autonomous Driving

Picture a self-driving car in the middle of rush hour. It's juggling data from cameras, LiDAR, and radar all at once, trying to track a pedestrian stepping off the curb just as a cyclist veers into its path. In that moment, every single millisecond counts. A lag of just 200 milliseconds could be the difference between a clean stop and a catastrophic accident.
This gets to the heart of the problem with autonomous systems: they produce a staggering amount of data that requires immediate action. A single vehicle can generate up to four terabytes of data every day. Trying to send that much information to the cloud and wait for instructions just isn't feasible.
The Reflex Analogy: Cloud vs. Edge
A great way to think about this is to compare it to your own reflexes versus a glitchy video call.
If you accidentally touch a hot stove, your hand pulls away instantly. That reaction is handled locally by your nervous system—it doesn't wait for a round trip to your brain for analysis. It's a local, immediate, and protective response. That’s precisely what edge computing does for a vehicle.
On the other hand, think about a video call with a bad connection. You see someone's mouth move, but the audio arrives a second later. That gap is latency, and it's what happens when data has to travel a long way to a server and back. For a self-driving car, relying on the cloud for critical decisions would be like trying to navigate traffic with that same video lag. It's just not safe.
Relying on a distant cloud for life-or-death decisions introduces an unacceptable level of risk. Edge computing ensures that critical functions like emergency braking, collision avoidance, and pedestrian recognition happen instantly, independent of network conditions.
A Founder’s Parallel: Scaling Challenges
For any founder, this problem should feel familiar. It’s a lot like the challenge of scaling an app from a simple prototype to something that can handle real-world user traffic. Your app might run flawlessly with a handful of users, but it can easily buckle under the strain of thousands of simultaneous requests.
Just as a web application needs a solid local cache or a content delivery network (CDN) to reduce lag and serve users quickly, an autonomous vehicle needs localized processing power to avoid system failure.
This is why edge computing in autonomous vehicles isn't just a nice-to-have feature; it's a fundamental requirement for safety, reliability, and basic functionality. It gives the vehicle the ability to think for itself when it matters most, creating a tough, resilient system that can handle the chaos of the real world.
The Three Layers of Vehicle Computing Architecture
To really get a handle on how autonomous vehicles think, it helps to stop seeing them as a single computer on wheels. Instead, picture a highly coordinated team with specialists at every level. This team has three distinct layers, each playing a critical role to keep the vehicle safe, smart, and responsive.
Let's break down this architecture with a simple analogy: an emergency response team.
This multi-layered approach isn't just a concept; it’s a direct reflection of how these systems are built in the real world. In the United States, for example, on-board edge computing is king, holding a massive 58% market share. Why? Because a car simply can't wait for a signal from a distant server to decide whether to slam on the brakes.
Hybrid models, which mix on-board processing with roadside units, make up another 29% and are perfect for things like fleet-wide analytics. The remaining 13% involves infrastructure-based edge, often found in cutting-edge smart city projects where the roads themselves are part of the network.
On-Vehicle Edge: The First Responder
The first and most important layer is the on-vehicle edge. This is the car itself—the boots on the ground, the first responder at the scene of the action. Its entire job is to make split-second, life-or-death decisions using data streaming in from its own sensors: cameras, LiDAR, and radar.
Think of it like a paramedic arriving at an accident. They don't have time to call a command center for instructions on how to perform CPR. They assess the situation and act immediately.
This layer is responsible for the urgent stuff:
- Object Detection: Spotting pedestrians, cyclists, and other cars in the immediate vicinity.
- Emergency Braking: Hitting the brakes now to avoid a collision.
- Lane Keeping: Making thousands of tiny steering corrections to stay perfectly centered.
All this processing happens right inside the vehicle, ensuring it can drive safely even if it loses its internet connection. It's the core of true autonomy.
Roadside Fog: The Local Command Post
Next up is the roadside fog, or what we often call "fog computing." If the car is the first responder, the fog layer is the local command post set up near the incident. It has more processing power and a broader view than a single vehicle but is still close enough to the action to be relevant in near real-time.
This layer consists of infrastructure like smart traffic lights, 5G cell towers, or dedicated roadside units (RSUs) that talk to nearby vehicles. Its job is to coordinate activity in a specific area, sharing critical information that a single car couldn't possibly see on its own.
A great example is a smart traffic light warning an approaching car about a pedestrian who just pushed the crosswalk button around a blind corner. The fog layer handles:
- Local Traffic Coordination: Optimizing traffic flow at a chaotic intersection for all vehicles.
- Vehicle-to-Infrastructure (V2I) Communication: Broadcasting alerts about accidents, black ice, or construction ahead.
- Peer-to-Peer Data Exchange: Letting vehicles share observations directly, like "Hey, there's a huge pothole 100 feet ahead."
Fog computing elegantly bridges the gap between the car's instant reflexes and the cloud's deep-thinking analysis. It creates localized pockets of intelligence that make entire traffic systems safer, not just individual cars.
The Cloud: The Central Headquarters
Finally, we have the central cloud. This is the main headquarters, located far from the action, where all the heavy-duty, big-picture analysis takes place. The cloud doesn't get involved in second-by-second driving decisions. Instead, it receives carefully selected, non-critical data from the entire fleet of vehicles.
Its role is absolutely essential for long-term improvement and system-wide intelligence. Key functions happening in the cloud include:
- AI Model Training: Using billions of miles of driving data from the whole fleet to train and improve the core driving algorithms.
- High-Definition Mapping: Constantly updating and distributing hyper-detailed 3D maps of every road.
- Over-the-Air (OTA) Updates: Pushing out new software features and critical safety patches to every vehicle simultaneously.
To get a clearer picture of how these layers work together, here’s a quick comparison:
Edge vs Fog vs Cloud in Autonomous Vehicles
This table breaks down the roles, latency, and primary tasks for each computing layer in the autonomous vehicle ecosystem.
| Computing Layer | Primary Role | Typical Latency | Example Tasks |
|---|---|---|---|
| On-Vehicle Edge | Instant, real-time decision-making for safety and control. | < 10 ms | Emergency braking, object detection, lane-keeping. |
| Roadside Fog | Local coordination and near real-time data exchange. | 10-50 ms | Traffic flow optimization, V2I hazard alerts. |
| Central Cloud | Big data analysis, model training, and fleet management. | > 100 ms | Training AI models, updating HD maps, OTA software updates. |
Each layer is optimized for a specific job, creating a system that is both incredibly responsive and continuously learning.
When combined, these three layers create a powerful, resilient system. This kind of structured, multi-tiered design is fundamental to building reliable systems at scale. You can learn more about these principles by exploring these software architecture best practices. This hybrid model perfectly balances immediate, life-saving reactions with deep, collective intelligence, forming the very backbone of modern autonomous driving.
Choosing the Right Hardware for Onboard AI
The AI in a self-driving car doesn’t just run on any old computer chip. It demands highly specialized hardware built for massive parallel processing. Getting a handle on the alphabet soup of processors—CPUs, GPUs, TPUs, and NPUs—is the first step to understanding how a vehicle actually thinks on the road.
Think of it like putting together a team of surgeons for a high-stakes operation. You wouldn't ask a general practitioner to perform brain surgery, right?
A standard CPU (Central Processing Unit) is that general practitioner. It's a jack-of-all-trades, fantastic at handling a wide variety of tasks one after another, from running the infotainment system to managing basic vehicle controls. But when you throw thousands of simultaneous calculations at it—the kind needed for real-time AI—a CPU just can't keep up. It becomes an instant bottleneck.
This is where the entire edge computing architecture comes into play, placing specialized hardware right where the action is: inside the vehicle.
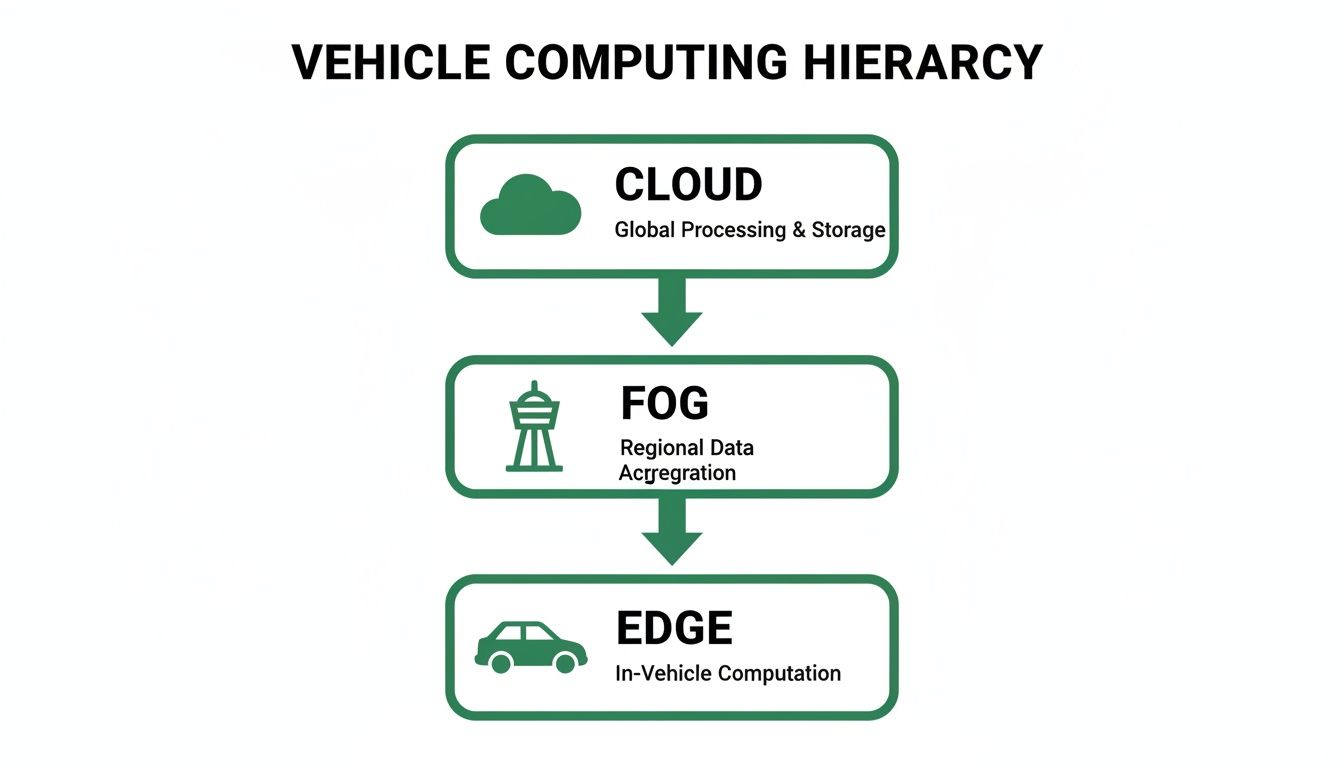
As you can see, the on-vehicle edge is the foundation for immediate, life-or-death decisions. The fog and cloud layers handle the bigger-picture, less time-sensitive work.
The Rise of AI Accelerators
To solve the CPU bottleneck, we turn to AI accelerators. These are specialized processors built from the ground up to handle the unique mathematics that power neural networks. They are the surgical specialists on our team, each one optimized for a very specific job.
The most famous of these is the GPU (Graphics Processing Unit). Originally invented to render slick graphics for video games, developers quickly realized their knack for parallel processing was a perfect fit for AI. GPUs can perform thousands of simple calculations all at once, making them a powerful and flexible choice for both training AI models in the cloud and running them for inference inside a vehicle.
But the quest for efficiency didn't stop there.
Key Insight: In the world of edge computing in autonomous vehicles, general-purpose hardware simply can't meet the demands for speed and efficiency. The industry's shift toward specialized AI accelerators is a direct response to the need for faster, more power-conscious processing right inside the car.
Specialized Processors: TPUs and NPUs
If a GPU is a versatile surgeon, then TPUs (Tensor Processing Units) and NPUs (Neural Processing Units) are the neurosurgeons. These are custom-built chips, known as Application-Specific Integrated Circuits (ASICs), designed with a single, obsessive focus: to execute neural network operations as fast and efficiently as humanly possible.
- Tensor Processing Units (TPUs): Developed by Google, TPUs are masters of the matrix multiplication that forms the backbone of deep learning. They strip away all the extra functionality found in a GPU, dedicating every last transistor to raw AI number-crunching.
- Neural Processing Units (NPUs): This is a broader category of AI-focused processors. Different companies build their own NPUs, but the mission is always the same: deliver the absolute best performance-per-watt for AI inference.
These highly specialized chips are what allow a vehicle to perform complex sensor fusion, seamlessly blending data from cameras, LiDAR, and radar into a single, cohesive picture of the world around it in real time.
Balancing Raw Power with Efficiency
For any founder or engineer working on autonomous vehicles, the core challenge is a constant balancing act between raw processing power and energy consumption. A car runs on a finite battery or fuel supply, and every watt of power the compute stack consumes directly eats into its operational range. This is a non-negotiable trade-off.
This is exactly why the efficiency of chips like TPUs and NPUs is so critical. Today’s cutting-edge AI chips can deliver an astonishing 26 tera-operations per second (TOPS) while sipping just 2.5 watts of power. That’s an efficiency of 10 TOPS per watt—roughly six times more efficient than what a traditional CPU could manage for the same AI task. This level of performance, detailed in current edge AI trends, enables the powerful data fusion needed for true contextual awareness in chaotic road conditions.
Ultimately, choosing the right hardware isn't just a technical detail; it's a fundamental strategic decision. It directly determines a vehicle's ability to make safe, split-second judgments without draining the very energy it needs to get to its destination.
How AI Models Are Managed at the Edge
The AI that powers an autonomous vehicle really lives a double life. There's the learning phase and the doing phase. It’s a lot like how we learn to drive a car ourselves—a long, slow period of intense study followed by a lifetime of split-second, reflexive actions on the road. In the AI world, we call these two parts training and inference.
Think back to getting your driver's license. That was the training phase. You had to absorb a mountain of information—traffic laws, road signs, parking techniques—and practice for hours. It was a slow, deliberate process that required a ton of data and feedback to build your core driving knowledge.
But when you're actually on the highway and a car suddenly cuts you off, you don't have time to consult your old driver's ed manual. You just react. That’s inference—taking all that deep-seated knowledge and applying it instantly to make a decision in the real world.
Training in the Cloud, Inference at the Edge
This analogy maps perfectly to how AI models work in autonomous vehicles. All the heavy-duty learning, the training, happens in the cloud. It has to.
Engineers funnel petabytes of real-world driving data from the entire vehicle fleet—camera feeds, LiDAR point clouds, radar returns—into colossal neural networks. These models live on sprawling server farms, churning through data to learn the subtle difference between a pedestrian and a mailbox or to predict where a cyclist is headed next.
Once trained, these models are brilliant but also massive and power-hungry. You could never stick one directly into a car. So, the next step is optimization. Using techniques like quantization and pruning, engineers shrink the model down, making it lean and fast without losing its critical accuracy. This lean, mean, optimized model is then sent to the vehicle's onboard computer for one job and one job only: inference.
In an AV system, the cloud is the university where the AI gets its education. The vehicle is the real world where it has to apply that knowledge on the job, every single millisecond. The edge is for doing, not for learning.
The Data Flywheel Continuous Improvement
Deploying the model to the car isn't the final step. It's actually the start of a powerful feedback loop that keeps the entire system getting smarter. As cars in the fleet navigate the world, they’re constantly encountering new and unusual situations, or "edge cases," where the AI might have hesitated or made a less-than-perfect prediction. This data is gold.
This powerful cycle is what's known as the data flywheel:
- Deploy: A new, optimized AI model is pushed out to the entire fleet using Over-the-Air (OTA) updates.
- Collect: A car encounters a rare scenario—a deer crossing a foggy mountain pass or a confusing set of construction signs—and sends that specific, high-value data back to the cloud.
- Analyze: Back at headquarters, engineers and automated tools comb through this new data, pinpointing weaknesses or gaps in the model's current understanding.
- Retrain: The huge central AI model in the cloud is retrained using this challenging new data, making it more resilient and capable.
- Repeat: A newly improved and optimized model is validated and deployed back out to the fleet, making every car safer.
This flywheel ensures the collective intelligence of the fleet grows over time. A lesson learned by one car in Arizona can be shared with every other car in the network. This continuous cycle of deploying, collecting, and retraining is what separates a static prototype from a living, evolving autonomous system. It requires a disciplined software workflow, much like how a development team will update a GitHub repository to roll out code changes in a safe, controlled way.
Navigating Security and Over-the-Air Updates

As an autonomous vehicle moves through the world, it’s not just driving—it's a constantly connected, data-processing hub making split-second, life-or-death decisions. This connectivity is its greatest strength, but it also paints a giant target on its back. When we talk about edge computing in autonomous vehicles, security can't just be a line item; it has to be the bedrock of the entire system.
Think about the sheer digital footprint of a modern car, what we call its attack surface. It's not just one computer. It’s the infotainment system, the GPS, and, most critically, the control units for steering and braking. Every single one of these connection points is a potential vulnerability.
Securing these edge devices requires a defense-in-depth approach. It all starts with encrypting data, both when it’s sitting on the vehicle's hardware and when it's being sent out. If someone intercepts it, it’s just gibberish. On top of that, good intrusion detection systems are non-negotiable—they act like a security guard for the car's internal network, watching for anything suspicious and ready to shut down threats before they can do any real damage.
Protecting the Vehicle and Its Data
The stakes couldn't be higher. It's not just about preventing a hacker from taking control of the wheel. We're also talking about an incredible amount of personal data. Autonomous vehicles learn our location history, driving habits, and sometimes even capture in-cabin video.
That data has to be locked down. This means strict access controls are essential, ensuring only validated software and authorized personnel can touch sensitive systems. The core ideas aren't entirely new; they echo many of the same principles used to protect user data in web development. In fact, many foundational security best practices for web applications are directly relevant here, as they all share the common goal of protecting sensitive information.
In a connected vehicle, a software vulnerability isn't just a bug—it's a potential safety crisis. The ability to securely and reliably patch that vulnerability remotely is one of the most critical operational capabilities for any autonomous fleet.
This constant need for updates brings us right to the other side of this coin: Over-the-Air updates.
Mastering Over-the-Air Updates
Over-the-Air (OTA) updates are the circulatory system for any modern autonomous fleet. It’s how manufacturers push out new features, fine-tune driving algorithms, and, most crucially, deploy urgent security patches. The days of needing a trip to the dealership for a simple software fix are over.
But sending a software update to a car that might be cruising down the highway is a genuinely tricky business. If it goes wrong, you could brick the vehicle and create a massive safety hazard. Because of this, the industry has settled on a few battle-tested patterns for delivering OTA updates safely. Any solid OTA strategy will have these elements:
- Secure Delivery: The update file itself must be encrypted and digitally signed to prove it came from the manufacturer. This stops an attacker from tricking the car into installing a malicious update.
- A/B Testing: You never push an update to the whole fleet at once. Instead, it goes to a small, controlled group of vehicles first. Engineers watch this group like a hawk to make sure everything works perfectly before a wider rollout.
- Robust Fail-safes: The vehicle has to be able to save itself. If an update fails halfway through, the system needs to automatically roll back to the last known good version. This guarantees the vehicle stays operational, no matter what.
These OTA patterns create the backbone for continuous, secure improvement. They let autonomous systems get smarter and safer over time, all while keeping the vehicle, its passengers, and their data secure on the road.
A Founder's Roadmap from Prototype to Production
Taking an autonomous vehicle from a controlled prototype to a production-ready fleet is a massive undertaking. For any founder, it feels a lot like evolving a startup from a scrappy MVP—held together with digital duct tape—to a robust platform that can handle real-world demand and pass investor due diligence.
Early-stage prototypes are all about speed. You grab off-the-shelf parts and cobble together software integrations to prove your concept quickly. That’s smart. But what works on a closed test track almost never survives the chaos of production, where things like reliability, security, and cost-efficiency suddenly become non-negotiable. The real engineering challenge is to methodically replace every one of those fragile pieces with something built to last.
Moving Beyond the Prototype Phase
The first real step is admitting your prototype is a temporary solution and planning its retirement. This forces you to make tough decisions on hardware and software that will define your company for years. You have to weigh the upfront cost of high-performance, automotive-grade hardware against the long-term operational cost of managing a fleet in the wild.
A huge piece of this puzzle is planning for hardware obsolescence. The AI chips and sensors that seem incredible today will be commodities in just a few years. Your architecture has to be modular, allowing you to swap out hardware components without having to redesign the entire system from the ground up. That flexibility is your lifeline for staying competitive and managing costs over the long haul.
You also have to get serious about your data backend. A prototype might just dump logs onto a local hard drive, but a production fleet needs a sophisticated data pipeline. This system has to be smart enough to collect, filter, and send only the most valuable data from thousands of vehicles back to your cloud. This is the engine that powers the data flywheel we talked about earlier.
For a founder trying to raise capital, the gap between a prototype and a production system is the difference between a science project and a real business. Investors don't fund fragile tech that breaks under pressure; they fund scalable, reliable platforms.
Owning Your Intellectual Property
Here’s the most critical part of the transition: you must own your core intellectual property (IP). Leaning on third-party platforms or "black box" solutions might get you started faster, but it introduces huge risks and fundamentally devalues your company. If you want to build a defensible moat around your business, you need to own the code that makes your system special.
This means strategically moving away from generic tools and building a stack that’s purpose-built for your needs. Taking this step pays off in several key ways:
- Investor Confidence: VCs are looking for proprietary technology. When you own your entire stack—from the inference engine on the vehicle to the data platform in the cloud—you're showing them a clear competitive advantage.
- Reduced Operational Costs: Building your own backend cuts out the expensive, recurring subscription fees for third-party tools. It gives you complete control over your operational spend.
- Enhanced Reliability: A custom-built system is just more stable than a patchwork of integrations. It’s designed from day one to handle your specific workload, which means fewer points of failure and better performance when things get busy.
Ultimately, the journey from prototype to production is all about deliberate, strategic engineering. It’s about building a foundation that not only works today but is also secure, scalable, and genuinely valuable tomorrow.
Diving Deeper: Your Edge Computing Questions Answered
Let's tackle some of the most common questions founders, engineers, and investors have about putting artificial intelligence on the road.
So, What Exactly Is Edge Computing in a Self-Driving Car?
In simple terms, edge computing means the car does its own thinking. Instead of shipping massive amounts of sensor data from cameras and LiDAR to a remote cloud server for analysis, the processing happens right there, inside the vehicle, on powerful, specialized hardware.
Think of it like the difference between a reflex and a conscious thought. When you touch a hot stove, your hand pulls back instantly without waiting for your brain to process the situation fully. That’s the edge—it’s the car’s built-in reflex system, making life-or-death decisions in a fraction of a second.
Can't We Just Use the Cloud for All This? It's So Powerful.
The cloud is an absolute beast for heavy-duty, non-urgent tasks. It's perfect for training the AI models on millions of miles of driving data or performing fleet-wide analytics. But for the immediate act of driving, it has a fatal flaw: latency.
The delay in sending data from the car to the cloud and waiting for instructions back is simply too long when a child runs into the street.
Relying on the cloud for critical driving decisions is like trying to play a fast-paced video game with a terrible internet connection. You’re always a step behind reality, and in driving, that lag can be catastrophic.
Even with the promise of 5G, you can't guarantee a perfect connection everywhere. What happens in a tunnel, a remote rural area, or a congested city center where the network is swamped? An autonomous vehicle must be able to operate safely on its own, and that's only possible with powerful onboard edge computing.
What Are the Biggest Hurdles to Getting This Right?
Making a car think for itself is far from simple. Engineers and product leaders are wrestling with some pretty significant challenges every day:
- Sky-High Hardware Costs: The advanced AI chips capable of handling this workload don't come cheap. These systems can add thousands of dollars to the cost of a vehicle.
- Power and Heat: These chips are not only expensive but also power-hungry and generate a ton of heat. In an electric vehicle, you have to balance performance against battery range, all while designing sophisticated cooling systems to prevent overheating.
- Security Nightmares: Putting a supercomputer on wheels makes it a very attractive target for hackers. Securing these systems against potential attacks is a massive and ongoing effort.
- The Balancing Act: Figuring out which computations must happen in the car and which can be offloaded to the cloud is a complex architectural puzzle with huge implications for cost, performance, and safety.
Who Are the Big Players in This Field?
The race to own the "brain" of the autonomous car is intense. On the hardware and platform side, you have giants like NVIDIA with its dominant Drive platforms, Intel's Mobileye, and Qualcomm pushing its Snapdragon Ride solutions.
Then you have the companies actually building and deploying the vehicles. Trailblazers like Tesla, Waymo (from Google's parent company, Alphabet), and Baidu (a major player in China) are all developing their own deeply integrated edge hardware and software stacks.
If you're a founder whose no-code prototype is hitting its limits, First Radicle can help. We turn fragile MVPs into production-grade software with a modern, scalable stack in just six weeks, guaranteed. Learn more at First Radicle.